



Dawei "David" Liang
Email: dawei dot liang @ utexas dot edu
About
I am a researcher and venture-backed startup founder based in San Diego, California. I received my Ph.D. in Computer Engineering from The University of Texas at Austin, where I was advised by Professor Edison Thomaz. My doctoral research spanned several interdisciplinary areas, including behavioral signal processing, audio and speech processing, human-centered AI, and digital health.
Currently, my work focuses on advancing clinical research and healthcare through AI-driven technologies. My recent work was recognized as a finalist at the 2025 Clinical Trial Recruitment Labs Symposium, sponsored by the University of Southern California and the Gates Foundation, and received a 2025 A2 Pilot Award sponsored by the National Institute on Aging and Johns Hopkins University.
Previously, I was named a Meta Ph.D. Fellow in 2023 (21 out of 3,200 Ph.D. applicants from over 100 universities worldwide, link). My research has also received a Best Paper Award at the IEEE ICASSP 2023 Ambient AI Workshop and a Best Paper Honorable Mention at ACM ISWC 2022.
Through both research and entrepreneurship, I am interested in building intelligent systems that help people better navigate healthcare and improve access to scientific discovery.
Education
The University of Texas at Austin, USA May, 2024
Ph.D. Computer Engineering
Advisor: Dr. Edison Thomaz
The University of Texas at Austin, USA Aug, 2023
M.S. Electrical and Computer Engineering
Advisor: Dr. Edison Thomaz
The University of Manchester, UK Jul, 2017
B.Eng. Electrical and Electronic Engineering
Advisors: Dr. Jovica Milanovic, Dr. Alex Casson
Academic Experience
The University of Texas at Austin, Austin, TX, USA 2024 – current
Associate / Affiliate Researcher
The University of Texas at Austin, Austin, TX, USA 2019 – 2023
Graduate Research Assistant
The University of Texas at Austin, Austin, TX, USA 2021 Fall
Graduate Teaching Assistant
ECE382V (Human Signals: Sensing / Analytics)
The University of Texas at Austin, Austin, TX, USA 2021 Spring
Graduate Teaching Assistant
EE379K (Machine Learning and Data Analytics for Edge AI)
Industrial Experience
Startup (in stealth mode), USA 2026 Spring - current
Founder and CEO
Billion Labs (part of UC San Diego), La Jolla, CA, USA 2025 Summer, Fall
Research Associate
Samsung Research America, Dallas, TX, USA 2024 Spring
Research Associate
Aizip, Cupertino, CA, USA 2023 Fall - 2024 Spring
Research Intern
Meta, Seattle, WA, USA 2022 Summer
Research Intern (Meta Reality Labs / Meta AI Applied Research)
Facebook, Remote / Austin, TX, USA 2021 Summer
Research Intern (Meta AI Applied Research)
Iodine Software, Austin, TX, USA 2019 Summer
Data Science Intern
Publications

Improving Audio Classification with Low-Sampled Microphone Input: An Empirical Study Using Model Self-Distillation
Dawei Liang, Alice Zhang, David Harwath, Edison Thomaz.
Interspeech 2024
This study introduces efficient methods for optimizing pre-trained audio neural networks (PANNs) targeting low-quality audio, employing Born-Again self-distillation (BASD) and a cross-sampling-rate self-distillation (CSSD) strategy. Testing three PANNs with diverse mobile datasets reveals that both strategies boost model inference performance, yielding an absolute accuracy / F1 gain ranging from 1% to 6% compared to a baseline without distillation, while sampling at very low rates (1 kHz - 2 kHz). Notably, CSSD shows greater benefits, suggesting models trained on high-quality audio adapt better to lower resolutions, despite the shift in input quality.

Automated Face-To-Face Conversation Detection on a Commodity Smartwatch with Acoustic Sensing [paper]
Dawei Liang, Alice Zhang, Edison Thomaz.
Proceedings of the ACM: Interactive, Mobile, Wearable and Ubiquitous Technologies (UbiComp / ISWC 2023)
In this paper, we present a practical approach for automatically detecting face-to-face conversations by leveraging the acoustic sensing capabilities of an off-the-shelf smartwatch. Our framework incorporates feature representations extracted from different neural network setups and shows the benefits of feature fusion. We evaluate our framework with 39 participants and in two settings, (1) semi-naturalistic and (2) free living, and the data was collected from 18 local families. Furthermore, we study the real-time capability of our framework by deploying a system on an actual smartwatch and showcase several strategies to improve its battrey usage in real life.

Dynamic Speech End-Point Detection with Regression Targets [paper]
Dawei Liang, Hang Su, Tarun Singh, Jay Mahadeokar, Shanil Puri, Jiedan Zhu, Edison Thomaz, Mike Seltzer.
The 2023 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2023)
In this paper, we propose a novel regression-based speech end-pointing model, which enables an end-pointer to adjust its detection behavior based on context of user queries. Specifically, we present a pause modeling method and show its effectiveness for dynamic end-pointing. Based on our experiments with vendor-collected smartphone and wearables speech queries, our strategy shows a better trade-off between endpointing latency and accuracy, compared to the traditional classification-based method.

AudioIMU: Enhancing Inertial Sensing-Based Activity Recognition with Acoustic Models [paper]
Dawei Liang, Guihong Li, Rebecca Adaimi, Radu Marculescu, Edison Thomaz.
The 2022 ACM International Symposium on Wearable Computers (UbiComp / ISWC 2022)
🏅 Best Paper Honorable Mention
This paper studies a novel approach to augment IMU models for human activity recognition (HAR) with the superior acoustic knowledge of activities. Specifically, we propose an audio-based teacher-student framework to derive an IMU-based HAR model. Based on a semi-controlled study with 15 participants, we show that an IMU model augmented with the proposed framework outperforms the original baseline model without augmentation.

A Dataset for Foreground Speech Analysis with Smartwatches in Everyday Home Environments [paper]
Dawei Liang, Zifan Xu, Yinuo Chen, Rebecca Adaimi, David Harwath, Edison Thomaz.
The 2023 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP Workshop 2023)
🏆 Best Paper Award
This paper introduces a dataset for foreground speech detection of users wearing a smartwatch. The data is collected from 39 participants interacting with family members in real homes. We then present a benchmark study for the dataset with different test setups. Furthermore, we explore a model-free heuristic method to identify foreground instances based on transfer learning embeddings.

Augmenting audio tagging systems by transferring voice knowledge: An empirical study [paper]
Dawei Liang, Yangyang Shi, Yun Wang, Nayan Singhal, Alex Xiao, Jonathan Shaw, Edison Thomaz, Ozlem Kalinli, Mike Sletzer.
arXiv preprint. 2021
This paper investigates the potential of transferring high-level voice representations extracted from a public speaker dataset to enrich an audio tagging pipeline. Towards this end, we develop a dual-branch neural network architecture based on TALNet, an advanced audio tagging system, for the joint learning of voice and acoustic features during a sound recognition process.
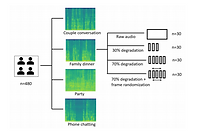
Characterizing the Effect of Audio Degradation on Privacy Perception And Inference Performance in Audio-Based Human Activity Recognition [paper]
Dawei Liang, Wenting Song, Edison Thomaz.
The 2020 ACM International Conference on Human-Computer Interaction with Mobile Devices and Services (MobileHCI 2020)
In this paper, we employ a mixed-methods approach to characterize the balance of privacy and inference performance in acoustic sensing. We first conduct an online survey with 266 participants to capture their perception of privacy qualitatively and quantitatively with degraded audio. Given our findings that privacy concerns can be significantly reduced at high levels of audio degradation, we then investigate how intentional degradation of audio frames can affect the recognition results of the target classes while maintaining effective privacy mitigation.

Audio-Based Activities of Daily Living (ADL) Recognition with Large-Scale Acoustic Embeddings from Online Videos [paper]
Dawei Liang, Edison Thomaz.
Proceedings of the ACM: Interactive, Mobile, Wearable and Ubiquitous Technologies (UbiComp / ISWC 2019)
This paper revisits the opportunity of training audio-based classifiers without the onerous and time-consuming task of annotating audio data. We propose a framework for audio-based activity recognition that can make use of millions of embedding features from public online video sound clips, and our framework does not require further feature processing or outliers filtering as in prior work. We evaluate our approach in the context of Activities of Daily Living (ADL) by recognizing 15 everyday activities with 14 participants in their own homes.
Community Service
Conference review: ACM UbiComp / ISWC, CHI, IEEE ICASSP, Interspeech, UIST, MSP, etc.
Journal review: ACM IMWUT, IJCNN
Technical program committee: Workshops @ Ubicomp / ISWC
Spare Time 🎨
-
I enjoy sports and outdoor activities a lot. I have spent years learning tennis and swimming. During my spare time, I also enjoy cycling, hiking, playing badminton, and playing Chinese chess (中国象棋) with my friends. I once won a gold medal for men's 4*400m relay and a silver medal for men's 400m during my high school 🥈
-
I had a rich experience (~ six years) of taking part in the Physics Olympiad in China before I went to college. This gives me a very unique opportunity to dive into our amazing world and understand how things are running in their way, from atoms to stars 🌌
-
I love traveling and exploring the world around me. I have been to 17 countries in the past few years for study or travel 🌏
-
I am a member of the UTCSSA Theater Club. I am glad to have those memorable moments at UT! ✨